


HHIDE_DUMP
Гость
H
HHIDE_DUMP
Гость
Сегодня мы с вами сделаем очень любопытный полиалфавитный шифр. А для начала немного о шифрах.

Шифры используются с незапамятных времён, сначала они были более простыми, например шифр Цезаря. В этом шифре буквы сдвигаются на несколько символов в ряду. Например А +3 будет Г. Такой шифр взламывается очень легко.
На смену ему появился моноалфавитный шифр или шифр подстановки. Вместо буквы в этом варианте может подставляться буква или цифра.
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВ
В этом шифре слово ВОДА будет ЕСЖГ. И всё так же расшифровка не составляет труда.
Важность сохранения тайны переписки всегда была очевидна - будь то донесения в армиях, любовные послания, и прочии варианты.
В итоге появился более сложный полиалфавитный шифр. В этом шифре уже используются несколько подстановочных шифров.
В сети куча информации по шифрам, не буду заостряться более на этом. Чтобы написать взломостойкий шифр нужно учесть некоторые моменты.
Вот видео, где человек очень подробно и доходчиво рассказывает и показывает как взломать шифр.
Рекомендую посмотреть сразу, чтобы понять слабые места. Если вы посмотрели, то можно отметить следующее:
1. Слова зашифрованные были с пробелами, и это круто облегчает криптоанализ.
2. В тексте использовался только один алфавит - русский, а значит его легко анализировать носителю языка.
3. Исходя из пункта 2, следует что увеличение длины ключа положительно скажется на взломостойкости. То есть в русском языке 33 буквы, это немного.
Однако ближе к делу - эти недостатки я устранил в новом шифре cipher")
Пишем в проге : explorer передаёт привет Codeby! а взамен получаем симпатичные иероглифы
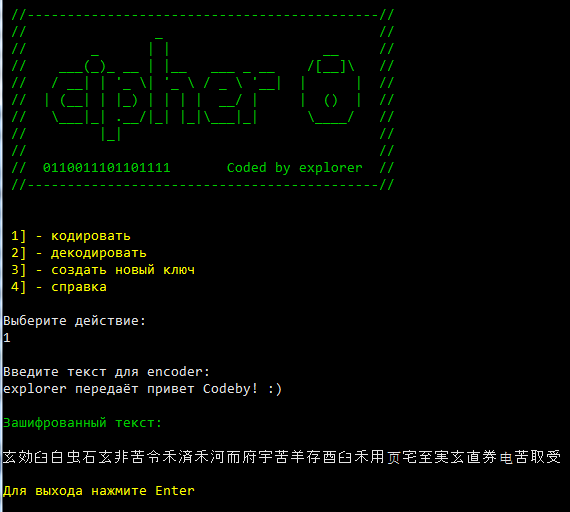
Ну а теперь будем разбираться что у нас делает программа и как она написана. Поехали!
Сначала импортируем модуль для отображения цветов и создадим класс с нужными цветами. Также рандомизатор для генерации нового ключа.
А вот теперь начинается самое интересное... Запишем вооооот такенные строки!
Что же мы наделали???
Для начала мы увеличили длину нашего ключа до 162 символов и перемешали. Туда вошли английские, русские буквы в обоих регистрах и имеющиеся на клавиатуре спец символы. Уже прекрасно, как мы видели на скриншоте выше, я использовал одновременно в своём сообщении смесь из русских и английских букв + спецсимволы. Это уже первый шаг к повышению взломостойкости.
Далее мы создали 3 подстановочных строки с иероглифами. Это ещё больше улучшает программу. Во-первых половина иероглифов там японских, а половина китайских ))) Итого у нас 4 языка. К тому ничто не мешает туда впихнуть корейских до кучи.
Далее создаём функцию справки, которую нужно поместить в текстовый файл readme.txt
Следующая функция это генератор ключа
Вот мы и добрались до самого главного - функции кодирования
Каким образом мы будем подменять исходный тест на иероглифы?
Ставим условие - если порядковый номер символа делится на 3 без остатка, то берём китайца из 4 списка, если делится на 2 без остатка, то из 3 списка, иначе со 2 списка. И таким образом мы добились, что повторяющихся символов будет очень мало.
Обратная функция дешифровки
Ну и выбор действия + выход по нажатию ENTER. Реализацию выхода конечно так делать неправильно, зато удобно.
А теперь проверим, работает ли функция расшифровки
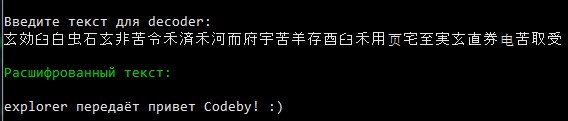
Все отлично. Как вы наверное уже заметили, в коде ещё добавлена куча исключений на случай неправильных действий пользователя.
Итого - плюсы и минусы в этой программе шифрования
+ слова не разделены пробелами
+ большая длина ключа 162 знака
+ возможность менять ключ через рандомизатор
+ используются много языков
+ используются трудночитаемые иероглифы
- текст шифровки имеет длину равную длине оригинального текста
- схему подстановки можно разгадать
В сухом остатке можно сказать что получилась прекрасная базовая программа, которую можно усложнить, убрав эти минусы.
КОД ПОЛНОСТЬЮ -
Шифры используются с незапамятных времён, сначала они были более простыми, например шифр Цезаря. В этом шифре буквы сдвигаются на несколько символов в ряду. Например А +3 будет Г. Такой шифр взламывается очень легко.
На смену ему появился моноалфавитный шифр или шифр подстановки. Вместо буквы в этом варианте может подставляться буква или цифра.
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВ
В этом шифре слово ВОДА будет ЕСЖГ. И всё так же расшифровка не составляет труда.
Важность сохранения тайны переписки всегда была очевидна - будь то донесения в армиях, любовные послания, и прочии варианты.
В итоге появился более сложный полиалфавитный шифр. В этом шифре уже используются несколько подстановочных шифров.
В сети куча информации по шифрам, не буду заостряться более на этом. Чтобы написать взломостойкий шифр нужно учесть некоторые моменты.
Вот видео, где человек очень подробно и доходчиво рассказывает и показывает как взломать шифр.
Рекомендую посмотреть сразу, чтобы понять слабые места. Если вы посмотрели, то можно отметить следующее:
1. Слова зашифрованные были с пробелами, и это круто облегчает криптоанализ.
2. В тексте использовался только один алфавит - русский, а значит его легко анализировать носителю языка.
3. Исходя из пункта 2, следует что увеличение длины ключа положительно скажется на взломостойкости. То есть в русском языке 33 буквы, это немного.
Однако ближе к делу - эти недостатки я устранил в новом шифре cipher
Пишем в проге : explorer передаёт привет Codeby!
а взамен получаем симпатичные иероглифы
Ну а теперь будем разбираться что у нас делает программа и как она написана. Поехали!
Сначала импортируем модуль для отображения цветов и создадим класс с нужными цветами. Также рандомизатор для генерации нового ключа.
Код:
# -*- coding:utf -8 -*-
# !/usr/bin/python3
import random
from colorama import init
init(autoreset=True)
class Bcolors:
GN = '\033[32m' # green
Y = '\033[93m' # yellow
R = '\033[91m' # red
Код:
# encoder
list_encoder = '''%Ёеуъ? 2v#;<\9}иЧRЯfA№e4УАЖn|=ёюя`ИLBНМ_ЪC0~ZwIHбпr'cbdqдgзВ"$Dэlхй,С-XF{Os(:БTжГ6zшЬJьkрpKEШЮХ]uGнЩ[YДQРт)W5N8U.7фxФ/ЛV!чiS1tЕТ3мjоЗmг^aвЭщPцскКПО&hMыа@yлЙoЦ+>*Ы'''
# encoder2
list_encoder2 = '''豸果禾申若念页祭瓜鸟龟足守电麦危幸曲実委用苦玄走武州巻立直虍捨网表岸各釆印担枚耒皮玉甩底瓦具述取而羊肉糸承因在艮性缶赤生考採並老長豕至甲机矛官向効府周件制版穴協板舌済定臼参宝石居波自角貝泣成呼共行令刷枝昔玊交白宇受岩法舟西龙季拝甘乳存襾耳再固艸宙血見聿次里治灰婦目身非禸田司米放宅妻衣刻由卒羽争邑供寺招的全券式舛虫酉毒宿届河'''
# list_encoder3
list_encoder3 = '''表昔龙石各守交枝具刻邑次瓦赤穴州周委協見担曲婦豸羽艮司危寺立府玄券参宝釆页的受乳武宅印呼玉艸在自岸令非老甩述実甲河波法皮糸由成宇白鸟虫虍麦舌申网定固制聿取甘妻宙幸巻缶岩龟承禸直存放生襾供豕共治舟身衣全泣貝耒官耳再刷矛走向果目玊若舛効考用念版电苦式机並長西居足酉羊性灰肉血瓜季臼件拝届毒里至禾米而争枚招行卒因角板底田祭採済捨宿'''
# encoder4
list_encoder4 = '''向米里存糸禾苦果次玉招成巻周届酉非卒河乳承禸定宇治述曲白供司老念目豕式波刻実羊泣府法瓜武舌釆网版玊聿石襾舟直具宅採再角妻虍毒缶血争鸟刷衣行寺官虫肉甘板長因危取耒印底協在足岩西自済臼豸季皮制甩艸龙龟矛考艮昔瓦見受用宿身各居邑祭並枝拝若走申全捨放岸由令舛呼电委券宝幸生担宙表穴効枚交机玄甲性赤件共耳立羽的麦而州婦灰貝至守固页参田'''Для начала мы увеличили длину нашего ключа до 162 символов и перемешали. Туда вошли английские, русские буквы в обоих регистрах и имеющиеся на клавиатуре спец символы. Уже прекрасно, как мы видели на скриншоте выше, я использовал одновременно в своём сообщении смесь из русских и английских букв + спецсимволы. Это уже первый шаг к повышению взломостойкости.
Далее мы создали 3 подстановочных строки с иероглифами. Это ещё больше улучшает программу. Во-первых половина иероглифов там японских, а половина китайских ))) Итого у нас 4 языка. К тому ничто не мешает туда впихнуть корейских до кучи.
Далее создаём функцию справки, которую нужно поместить в текстовый файл readme.txt
Код:
readme():
try:
handle = open("readme.txt", "r")
data = handle.read()
print(Bcolors.GN + data)
handle.close()
except IOError:
print(Bcolors.R + 'Файл справки не обнаружен!')
Код:
# new key
def key():
w = list_encoder
q = ''.join(random.sample(w, len(w)))
print('')
print(Bcolors.GN + q)
Код:
def enc():
while True:
b = input('\n' + 'Введите текст для encoder: '+'\n')
if b == '':
print(Bcolors.R + "Ничего не введено!")
continue
h = b + list_encoder
if len(list_encoder) != len(set(h)):
print(Bcolors.R + 'Символы в ключе не найдены!')
continue
print(Bcolors.GN + '\n' + 'Зашифрованный текст:' + '\n')
i = 1
for c in b:
encoder = ''
y = list_encoder.index(c)
if i % 3 == 0:
encoder += list_encoder4[y]
elif i % 2 == 0:
encoder += list_encoder3[y]
else:
encoder += list_encoder2[y]
i += 1
print(encoder, end="")
breakСтавим условие - если порядковый номер символа делится на 3 без остатка, то берём китайца из 4 списка, если делится на 2 без остатка, то из 3 списка, иначе со 2 списка. И таким образом мы добились, что повторяющихся символов будет очень мало.
Обратная функция дешифровки
Код:
def dec():
while True:
m = input('\n' + 'Введите текст для decoder: '+'\n')
if m == '':
print(Bcolors.R + "Ничего не введено!")
continue
t = m + list_encoder2
if len(list_encoder2) != len(set(t)):
print(Bcolors.R + 'Символы в ключе не найдены!')
continue
print(Bcolors.GN + '\n' + 'Расшифрованный текст:' + '\n')
i = 1
for x in m:
decoder = ''
if i % 3 == 0:
y = list_encoder4.index(x)
decoder += list_encoder[y]
elif i % 2 == 0:
y = list_encoder3.index(x)
decoder += list_encoder[y]
else:
y = list_encoder2.index(x)
decoder += list_encoder[y]
i += 1
print(decoder, end="")
break
Код:
while True:
text_vybor = input('Выберите действие:'+'\n')
if text_vybor == "1":
enc()
break
elif text_vybor == "2":
dec()
break
elif text_vybor == "3":
key()
break
elif text_vybor == "4":
readme()
break
else:
print(Bcolors.R + "Введите 1,2,3 или 4!")
print(Bcolors.Y + "\n\nДля выхода нажмите Enter")
input()Все отлично. Как вы наверное уже заметили, в коде ещё добавлена куча исключений на случай неправильных действий пользователя.
Итого - плюсы и минусы в этой программе шифрования
+ слова не разделены пробелами
+ большая длина ключа 162 знака
+ возможность менять ключ через рандомизатор
+ используются много языков
+ используются трудночитаемые иероглифы
- текст шифровки имеет длину равную длине оригинального текста
- схему подстановки можно разгадать
В сухом остатке можно сказать что получилась прекрасная базовая программа, которую можно усложнить, убрав эти минусы.
КОД ПОЛНОСТЬЮ -